4中數(shù)據(jù)類型為: int32、int64、float、double 。
當(dāng)然,里面還有一些64為地址和32位地址的區(qū)別,因此又增加了一些列的東西,我個人認為其中最常用的函數(shù)只有4個,分別是:_mm_i32gather_epi32 、_mm256_i32gather_epi32、_mm_i32gather_ps、_mm256_i32gather_ps,我們以_mm256_i32gather_epi32為例 。
注意,這里所以下,不要以為_mm_i32gather_ps這樣的intrinsics指令以_mm開頭,他就是屬于SSE的指令,實際行他并不是,他是屬于AVX2的,只是高級別的指令集對老指令的有效補充 。
_mm256_i32gather_epi32的相關(guān)說明如下:
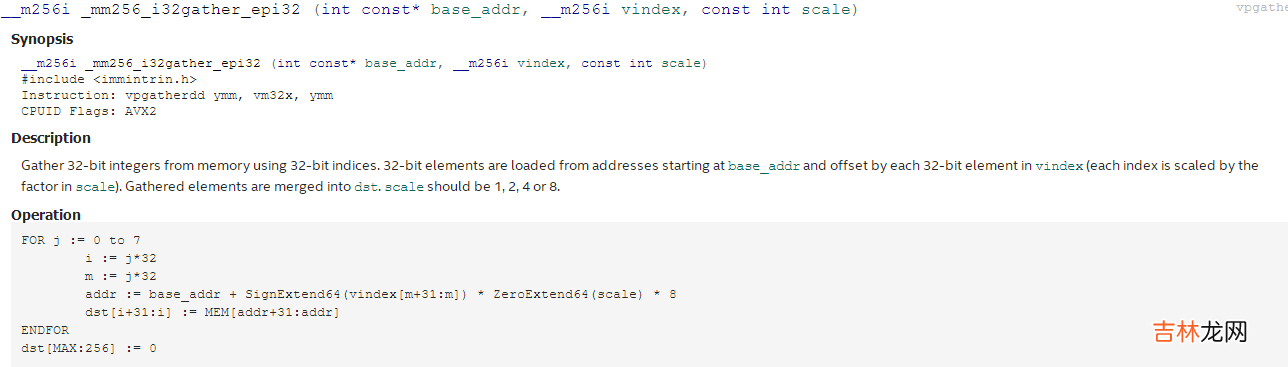
文章插圖
其作用,翻譯過來就是從固定的基地址base_addr開始,燃用偏移量由 vindex提供,注意這里的vindex是一個__m256i數(shù)據(jù)類型,里面的數(shù)據(jù)要把它看成8個int32類型,即保存了8個數(shù)據(jù)的地址偏移量,最后一個scale表示地址偏移量的放大系數(shù),容許的值只有1、2、4、8,代表了字節(jié),雙字節(jié),四字節(jié)和把字節(jié)的意思,通常_mm256_i32gather_epi32一般都是使用的4這個數(shù)據(jù) 。
那么注意看這些gather函數(shù),最下的操作單位都是int32,因此,如果我們的查找表是byte或者short類型,這個就有點困難了,正如我們上面的Cure函數(shù)一樣,是無法直接使用這個函數(shù)的 。
【AVX圖像算法優(yōu)化系列二: 使用AVX2指令集加速查表算法。】那么我我們來看看一個正常的int型表,使用兩者之間大概有什么區(qū)別呢,以及是如何使用該函數(shù)的,為了測試公平,我把正常的查找表也做了展開 。
int main(){const int Length = 4000 * 4000;int *Src = https://www.huyubaike.com/biancheng/(int *)calloc(Length, sizeof(int));int *Dest = (int *)calloc(Length, sizeof(int));int *Table = (int *)calloc(65536, sizeof(int));for (int Y = 0; Y < Length; Y++)Src[Y] = rand();//產(chǎn)生的隨機數(shù)在0-65535之間,正好符號前面表的大小for (int Y = 0; Y < 65536; Y++){Table[Y] = 65535 - Y;//隨意的分配一些數(shù)據(jù)}LARGE_INTEGER nFreq;//LARGE_INTEGER在64位系統(tǒng)中是LONGLONG,在32位系統(tǒng)中是高低兩個32位的LONG,在windows.h中通過預(yù)編譯宏作定義LARGE_INTEGER nBeginTime;//記錄開始時的計數(shù)器的值LARGE_INTEGER nEndTime;//記錄停止時的計數(shù)器的值double time;QueryPerformanceFrequency(&nFreq);//獲取系統(tǒng)時鐘頻率QueryPerformanceCounter(&nBeginTime);//獲取開始時刻計數(shù)值for (int Y = 0; Y < Length; Y += 4){Dest[Y + 0] = Table[Src[Y + 0]];Dest[Y + 1] = Table[Src[Y + 1]];Dest[Y + 2] = Table[Src[Y + 2]];Dest[Y + 3] = Table[Src[Y + 3]];}QueryPerformanceCounter(&nEndTime);//獲取停止時刻計數(shù)值time = (double)(nEndTime.QuadPart - nBeginTime.QuadPart) * 1000 / (double)nFreq.QuadPart;//(開始-停止)/頻率即為秒數(shù),精確到小數(shù)點后6位printf("%f\n", time);QueryPerformanceCounter(&nBeginTime);//獲取開始時刻計數(shù)值for (int Y = 0; Y < Length; Y += 16){__m256i Index0 = _mm256_loadu_si256((__m256i *)(Src + Y));__m256i Index1 = _mm256_loadu_si256((__m256i *)(Src + Y + 8));__m256i Value0 = _mm256_i32gather_epi32(Table, Index0, 4);__m256i Value1 = _mm256_i32gather_epi32(Table, Index1, 4);_mm256_storeu_si256((__m256i *)(Dest + Y), Value0);_mm256_storeu_si256((__m256i *)(Dest + Y + 8), Value1);}QueryPerformanceCounter(&nEndTime);//獲取停止時刻計數(shù)值time = (double)(nEndTime.QuadPart - nBeginTime.QuadPart) * 1000 / (double)nFreq.QuadPart;//(開始-停止)/頻率即為秒數(shù),精確到小數(shù)點后6位printf("%f\n", time);free(Src);free(Dest);free(Table);getchar();return 0;}直接使用這句即可完成查表工作:__m256i Value0 = _mm256_i32gather_epi32(Table, Index0, 4);
這是一個比較簡單的應(yīng)用場景,在我本機的測試中,普通C語言的耗時大概是27ms,AVX版本的算法那耗時大概是17ms,速度有1/3的提升 。考慮到加載內(nèi)存和保存數(shù)據(jù)在本代碼中占用的比重明顯較大,因此,提速還是相當(dāng)明顯的 。
經(jīng)驗總結(jié)擴展閱讀
















- BLS簽名算法
- 從源碼分析 MGR 的新主選舉算法
- Upscayl,免費開源的 AI 圖像增強軟件
- GC plan_phase二叉樹掛接的一個算法
- AVX圖像算法優(yōu)化系列一: 初步接觸AVX。
- 含源碼 手把手教你使用LabVIEW OpenCV dnn實現(xiàn)圖像分類
- 什么是a3算法
- 根號加根號怎么算
- 獨辟蹊徑:逆推Krpano切圖算法,實現(xiàn)在瀏覽器切多層級瓦片圖
- 數(shù)列的四種表示方法